

Minimising Correlated Failures in Distributed Systems
Designing distributed systems to minimise correlated failures.

I am a seasoned Software Engineer with over 8 years of diverse experience, primarily focusing on Backend Software Engineering and Complex systems.
Scalability and dependability are two areas where distributed systems face new problems. When many services are hosted on separate computers, they must use network protocols to talk to one another. The more the variety of services available, the greater the likelihood that something will go wrong. Distributed systems will inevitably experience some form of failure; the important thing is how you plan to handle it. Furthermore, if your system is hosted on cloud infrastructure's virtual machines (VMs), failures can have knock-on repercussions for other customers who are utilising the same physical hardware. This article explores the topic of improving the resilience of large-scale distributed systems in the face of failure.
Introduction
Distributed systems are complex. They involve many different processes and services that can fail or degrade independently. As a result, distributed applications need to be able to handle these failures gracefully. This article outlines five techniques for minimizing correlated failures in distributed systems:
failure isolation,
defensive coding,
continuous monitoring,
peer review, and
Immutable APIs.
These techniques help developers avoid the most common sources of correlated failures in software stacks and services across all layers of the stack and make it easier to debug issues when they do occur. These techniques will not eliminate every instance of correlated failures across your system’s architecture, but they will go a long way toward reducing their presence and impact on your end users.
The Challenges of Scalability and Reliability
Distributed systems handle a large amount of data across a network of systems that may be geographically distributed. Distributed systems are more complex than centralized systems, but they can also be more efficient and scalable because they can employ additional computing resources.
For example, you might use a distributed system if you need to analyze data in a very large database that can’t be processed on one computer. Distributed systems also have their unique challenges related to scalability and reliability.
To explain; let’s take a look at the high-level architecture of a typical distributed system:
Distributed system architectures follow a standard pattern where data is ingested into a centralized data store.
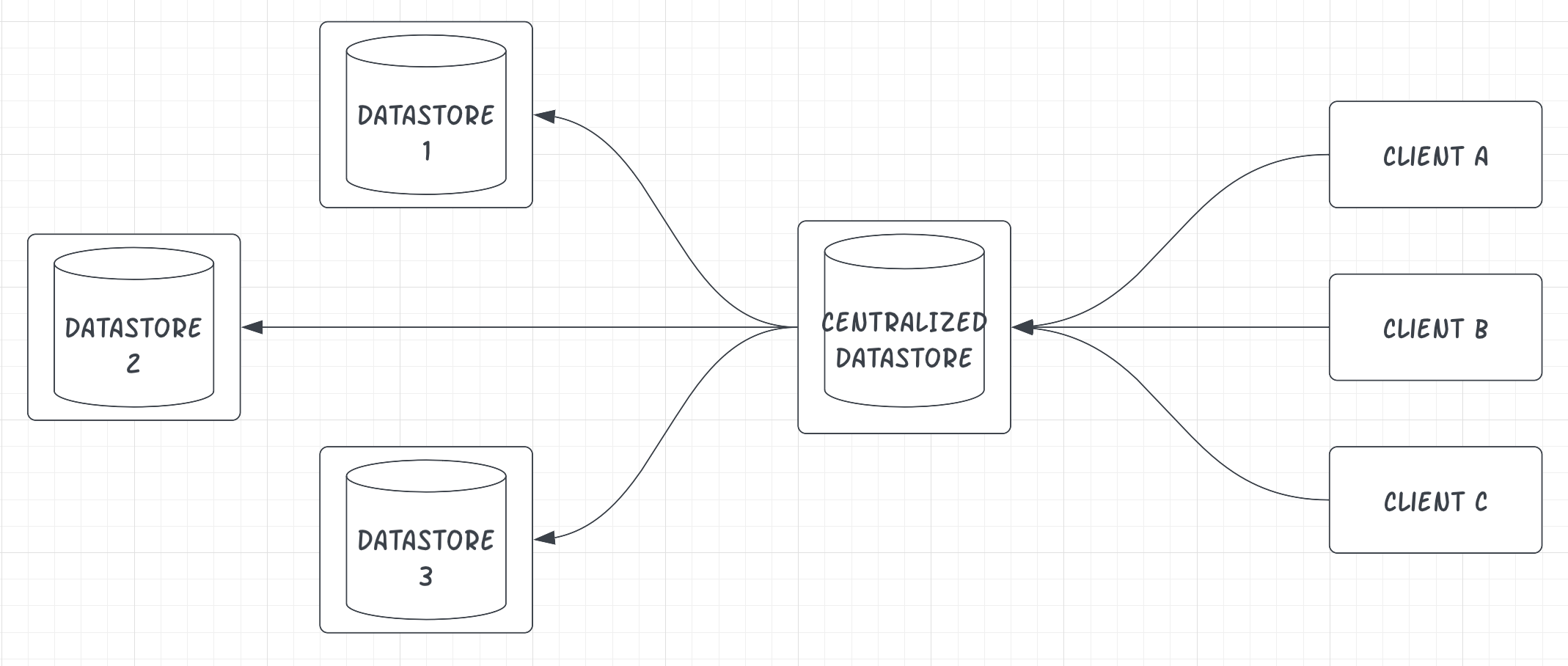
This data store is responsible for replicating and distributing that data to other data stores that are spread across the network. If you’re building a distributed system, it’s important to understand that these data stores are not equally reliable.
Each data store has its unique level of availability and reliability. In many ways, this is what makes distributed systems difficult to build. You have to account for these differences, and you have to account for the fact that systems inevitably fail. In other words, distributed systems are fragile by default. You have to do things (and lots of things) differently to make them reliable.
Why is it so hard to build reliable distributed systems?
The central challenge of building a distributed system is that the system itself is distributed — all the components are distributed across different locations. Distributed systems pose unique reliability challenges that can’t be solved with a single, centralized approach because that centralized approach will only be as reliable as the weakest component. When something fails, it can impact the entire system, and distributed systems are always susceptible to failure.
Identifying the Critical Path in Distributed Systems
When you’re trying to optimize a distributed system, the first step is to identify the critical path. The critical path is the path that determines the overall availability of the system. The critical path is the path that takes the longest amount of time to complete. It’s the path where a failure will have the most impact on the system as a whole. If this path fails, the entire system will be at risk of failing.
To identify the critical path, you have to look at everything that your system does. You have to understand every operation that your system performs and every operation that each component of your system performs. Once you’ve identified the critical path, you can focus your attention on making that path as reliable as possible. The less reliable the path, the more attention you should give to it.
Use Redundancy to Reduce Failures in Distributed Systems
Redundancy is the ability to withstand failure by having multiple redundant components that can take over if a component fails. It is a common technique used to improve the availability of distributed systems because it enables you to make the critical path more reliable by adding more components to that path.
The more components you have performing a single operation, the less likely each component is to fail. There are many different kinds of redundancy you can use in distributed systems, including:
Automated failover - Automated failover uses a secondary component to take over when the primary component fails. This can be as simple as having a system that triggers a human to manually take over when a component fails.
Service-level agreement (SLA) - An SLA is an agreement between a service owner and a client that specifies the level of availability and performance the system will maintain.
Load balancing - Load balancing distributes the workload across multiple components. This can be useful for distributing the workload across multiple instances of an application or across instances of multiple applications.
Redundant data stores - Redundant data stores allow you to write the same data to multiple copies of a data store. This helps to ensure that the data will be retained in the event that one data store fails.
Use Failure Detection to Repair Your System After a Failure Occurs
Failure detection is the process of monitoring your system to identify when it fails. For example, you can detect a failure when a service is unavailable or when it returns an error. There are several different techniques for detecting failures, but some of the most common include:
Timeouts - Timeouts can be used to detect when a service is taking too long to respond. This is especially useful when communicating with services hosted on different networks.
Retry logic - Retry logic can be used to detect when a service is unavailable by retrying the request until it succeeds.
Circuit breakers - Circuit breakers can be used to detect when a service is failing and automatically stop sending requests to that service.
Thresholds - Thresholds can be used to trigger an alert when a metric crosses a certain threshold. - Outages - Outages are when a service is completely unavailable.
Don’t Rely on One Thing When Building a Distributed System
One of the most important things to remember when building a distributed system is that you can’t rely on any single component to provide 100% uptime. You can’t rely on a single data store, a single network, or a single service. Instead, you have to build the system in such a way that it can survive even when one or more components fail. You have to build the system in such a way that it can withstand the occasional, inevitable failure of a component. To do that, you have to design the system to be fault-tolerant by using the following principles:
Isolation - Isolation is the ability to run one component as an independent unit. This means that the failure of one component won’t impact the other components in the system.
Decoupling - Decoupling is the ability of components to communicate without depending on each other. This means that the failure of one component won’t impact the other components in the system.
Redundancy - Redundancy is the ability to withstand failure by using multiple components to perform the same task. This means that the failure of one component won’t impact the other components in the system.
More Techniques for avoiding correlated failures
The most fundamental truth of distributed systems is that they often experience failures. There will always be unexpected problems, no matter how meticulously you plan and test your system. To construct distributed systems that are both scalable and trustworthy, it is essential to learn how to handle these errors.
Failure Isolation
The key to dealing with failures is to minimize the side effects of those failures. This means isolating the part of the system that failed from the rest of the system. The best way to do this is to design your system so that each component can be operated in isolation. This lets you scale systems horizontally by adding more capacity without adding the risk of cascading failure.
Defensive Coding
Defensive coding is another important part of the design of distributed systems. Building a distributed system requires a different way of thinking than building an application that runs on a single server. Distributed systems must consider stability, scalability, and performance, unlike single-server apps.
Distributed systems, in particular, must follow the best practices for handling errors, especially when it comes to dealing with unplanned events like network and hardware failures. That means you have to handle all errors with grace, not just fatal ones. Distributed systems have different requirements than single-server apps, making error handling difficult. Hardware and network may fail, thus, distributed systems must be designed to manage failures as normal.
Continuous Monitoring
Monitoring and logging play a significant role in the design of distributed systems. This is because it can be difficult to keep track of the numerous moving elements that distributed systems frequently contain. In particular, sharding is frequently used to scale distributed systems that rely on distributed databases. Data distribution across numerous machines is called sharding. How do you identify the downed machines and the missing data if your distributed system depends on a sharded database? How may communication errors between database shards be found?
Monitoring entails more than only monitoring uptime. It involves monitoring every element that affects uptime. Monitoring must also be spread in a distributed system. Distributed components cannot be monitored by a centralised monitoring solution. Similar to centralised data, dispersed monitoring systems won't be able to collect it.
Peer Review
Reviewing your code with new eyes is one of the best ways to stop bugs from entering. Peer reviews should be conducted as soon as possible after the design phase of distributed systems is complete. This will find as many problems and design flaws up-front before the code is even put into use. You can spot possible difficulties before they become serious issues that need to be corrected by showing your design to a coworker. There are a few various approaches you can take. You can use a collaborative tool like a shared document or a design review board or you can present your design to a colleague in person.
Immutable API
API design is also crucial in developing distributed systems. In the context of distributed systems, APIs serve as the connecting tissue. It's not enough to develop an API and cross your fingers. A well-designed API is essential. An immutable API design is one approach. Simply said, an immutable API design is one in which the API endpoints are built exclusively for CRUD operations (creating, reading, updating, and deleting) in a way that prevents data alteration. There are a couple of reasons why this matters. As a result, your API can scale more easily without you having to handle concurrency or resource-locking issues. The only guarantee in distributed systems is that something will go wrong. The risk of a single component failure triggering a cascading failure across the system is mitigated if the API is designed to prevent data alteration.
Summing up
Distributed systems present new challenges in scalability and reliability. When all services reside on different machines, they must communicate with one another through networked protocols. The more services there are, the more opportunities there are for something to go wrong. Failure is a natural part of distributed systems, but it’s how you deal with that failure that matters most. To handle this, you can use redundancy to reduce failures, use failure detection to repair the system after a failure occurs, and don't rely on one thing when building a distributed system. Distributed systems are challenging to build, but they are also powerful and scalable. To optimize them, you have to understand the critical path and focus on making them as reliable as possible.




